
|
|
1) ハングルとはどんな文字か?
ハングル(訓民正音)は1446年、李氏朝鮮第四代国王である世宗大王の命を受けた集賢殿(研究所)の学者たちによって考案され、同大王によって公布された表音文字です。「字母」ないしは「字素」と呼ばれる文字の部品を組み立てることで、あらゆる発音を表現できるのが最大の特徴です。
公布以来550年余、徐々に形を変えながら現在では母音10、子音14に整理されています。子音字母は初声(文字の頭)に来るとは限らず、終声(パッチムとも呼ばれ、母音のあとに来る)になることもあります。
1つの文字は初声+中声(母音字素)、または初声+中声+終声で構成されますが、終声は1つとは限らず、2つになることもあります。使われなくなった字素(古語)を除いた現代ハングルの組み合わせ数は、実に11,172通りにも上ります。
2) コンピュータ以前のハングル機械化
韓国にあって日本や中国にないものに「タイプライター文化」があります。韓国はシンガポールのような都市国家を除けば、アジアで有数のパソコン世帯普及率(1997年の時点で約40%、日本は約20%)を誇っていますが、韓国でここまでパソコンが普及したのは、朝鮮解放直後の40年代末から積み上げられてきたハングル・タイプライター文化の継承にほかなりません。韓国には「キーボード・アレルギー」という言葉は存在しないのです。
1949年、医師の公炳禹(コン・ビョンウ)博士によって初めてハングルのタイプライターが開発されました。公博士のタイプライターはハングルを初声・中声・終声に分類し、それぞれにキーを割り当てました。これが「3ボル(※1)式」タイプライターの原型です。
後に子音(初声・終声を兼ねる)と母音で構成する「2ボル式」、終声字素(パッチム)がある場合とない場合で母音(中声)字素の活字が異なる「4ボル式」なども開発され、大別して3種類の配列が存在していました。
これら「〜ボル式」の違いは、キーボードの配列にとどまりません。構造的にも2ボル式タイプライターは1種類の活字を初声と終声用に使い分けるのに対し、3ボル式ではそれが別々になっています。書体のデザインも異なります。初声・終声用書体が区別されている「3ボル式書体」のほうが、初声と終声が兼用で中途半端なデザインの「2ボル式書体」よりも美しいのですが、2ボル式にはキー配列数が少なく覚えやすいという特徴があります。一般の印刷物や現在のほとんどのコンピュータ書体で用いられる正方形フォントと比較して、最も違和感のないのは中声字素を終声の有無で使い分ける4ボル式ですが、キー配列数が最も多く、構造的にも複雑で打ちにくいとされています。
3ボル式書体は、雑誌の題字から広まった「セムムル体(セミキプンムル体)」などの原型となりました。認識速度などの点から、一見でこぼこした3ボル式書体のほうが正方形書体よりも優れているという指摘もあります。
4ボル式はタイプライターにのみ存在しましたが、2ボル式と3ボル式、そしてその特徴は、今のパソコンのキーボード配列や書体にもそのまま引き継がれています。詳しくは後述します。
ハングル・タイプライターは、1980年代までハングルの機械化を先導してきました。ソウルはもちろん、地方都市にもタイプライター学院(塾)が続々と作られ、商業高校でもハングル・タイプライターを教えていました。
1990年代には、パソコンの低価格・高性能化によってパソコンのキーボードとワープロソフトに取って代わられ、タイプライター学院の多くはそのままコンピュータ(パソコン)学院となりましたが、機械化に適したハングルによって豊かな文字文化が育まれてきたといえます。
※1 「ボル([beol])」というのは韓国・朝鮮の固有語(漢字で表記できない)で「組」とか「(洋服などの)上下揃え」を意味します。日本語では「2組式」「3揃式」などと訳されたこともありましたが、日本語を母国語とする人が韓国に行って「2ジョシク」「3チョンシク」などと誤用するのを避けるため、「ボル」をそのまま用いるようになったと考えてください。
3) ハングルコードの誕生と変遷
ハングルが初めてコンピュータ(メインフレーム)上に載ったのは1970年代のことで、当初は初声・中声・終声の字素ごとにそれぞれ1バイト(7もしくは8ビット)ずつを割り当て、1文字(完成状態のハングル)あたり2〜5バイトで構成される「Nバイトハングルコード」が使われていました。基本的にタイプライターの考え方をそのまま持ち込んだもので、字母を単純に組み立てる方法です。韓国初のパソコン(三宝コンピュータによるシャープMZ-80Kクローン)、MSX1(MSX2は後述の常用組み合わせ型)、Apple][クローンといった初期の8ビットパソコンや、UNIXワークステーションの一部でも使われたようです。
しかし、可変データ長のNバイトハングルでは、データ処理(とくに表示)にさまざまな制約が加わり、データ量も増加することになるため、やがて1つの完成文字につき2バイトとなるように工夫された固定長のハングルコードが登場することになります。
2バイトのハングルコード体系は、次の2つに大別できます。
韓国では1984年からIBM PC互換機の本格的な生産が開始されましたが、最初から2バイト系ハングルコードが主流となり、そのほとんどは組み合わせ型体系を採用しました。ハングルの表現に制限がないうえ、フォントのデータ量が少なくて済むのもメリットとされていたようです。その代わり、当時コンピュータを対象とした文字コードの国家標準が存在しなかったため、PCの大手メーカー各社はバラバラにハングルコードを定めました。
主要な組み合わせ型ハングルコードだけでも、後に常用組み合わせ型(※2)と呼ばれるようになった三宝コンピュータの「三宝組み合わせ型」以外に、三星電子と金星社の独自コードがありました。また、詳細は不明ながら現在のKS(韓国産業標準)完成型が制定される1987年以前には、組み合わせ型のKSコードが存在していたこともあるようです。DOS時代に広く用いられた「CHAMEL(カメレオン)」というハングルコードコンバータでは、「旧KS組み合わせ型」コードをサポートしています。
※2 厳密に言えば、常用組み合わせ型にもいろいろあり、現在一般にそう呼ばれているのはKS完成型コード(後述)の登場後に、KSコードの漢字と2バイト記号部分に対する互換性を持たせて改正された、KSSM(Korea Specification Support Model)と呼ばれるコード体系です。KSSM以前の常用(三宝)組み合わせ型は一般にTG(TriGem=三宝)コードと呼ばれており、ほかに当時大宇通信でも三宝組み合わせ型をベースとしたコードを採用していました。これらKSSM以前の常用組み合わせ型コードには、いずれも2バイト記号部分の互換性はありませんし、漢字の扱いも明確には規定されていませんでした。もちろん、ハングルと1バイト英数・記号についてはすべての常用組み合わせ型コードの間で互換性があります。
こうして組み合わせ型を中心に2バイトハングル処理の普及が進むなか、数少ない例外として「7ビット完成型ハングルコード」がありました、これは完成ハングル1文字につき英数字(ASCIIコード、1文字あたり7ビット)2文字分、つまり14ビットで表現する体系であり、並んで用いられる頻度の低い英数字2字の組み合わせをハングル1文字に変換するという手法で、ハングルの表示と入力を実現していました。
このコードは、「英語版ソフトでハングルを通す」という目的のみをめざして考案され、韓国産の優秀なソフトウェアが少なかった1980年代中〜後半当時のニーズに応えたものですが、16ビット系コードとは異なり、入力された文字がハングルかどうかを判別する手段がありませんでした。よって、行末での改行や折り返しで文字化けしたり、英数字の組み合わせによっては英文テキストデータが文字化けしてしまうことも多く、不便でした。ちなみにこの7ビットハングルは、当時ソウル随一の電気街だった「鍾路世運商街」のパソコンショップの技術者が開発したことから、世運商街のある地名を取って「清渓川ハングルコード」とも呼ばれました。
また、大宇電子(現在、大宇電子のコンピュータ事業は大宇通信のそれに統合されていますが、1990年代はじめまでは両者が別々にパソコンを製造・販売していました)では、清渓川コードと同じ方法論ながら、異なるコード配列で実現していた「DH7ビットハングル」を持っていました。
4) KS完成型の登場
現在のWindowsなどでの標準ハングルコードであるKS C 5601-1987(KS完成型)は、それまでの旧KS組み合わせ型ハングルコードに代わる新しい「情報交換用符号(ハングルおよび漢字)」として、1987年に制定されたものです。
KS(Korean National Standard=韓国産業標準)とは日本のJISとJASを合わせたような国家標準規格で、コンピュータの関連では文字コード(文字セットおよびコード配置)に加え、キーボード配列などにもKSが適用されています。
いったんは国家標準となった組み合わせ型に、完成型が取って代わった背景には、組み合わせ型文字コードが特定の字母の組み合わせによっていわゆる「メタ文字」を発生し、当時普及しはじめていたパケット交換方式によるデータ通信サービス(日本で言うDDXやVENUS-P、韓国ならDNSやHINET-P)上で障害を起こすため、通信用の文字コードとして不向きであったことが挙げられます。
しかし、このコードの文字セットでは、4,888の漢字(日本でいう旧字体のみ)や、日本語のひらがな・カタカナが追加(長母音「ー」がないとか、いくつか欠陥もありますが)される一方で、肝心のハングルがわずか2,350字に制限されてしまいました。これで日常的に用いられるハングルの99%は表記可能とされていますが、逆に1%の表記できない文字が存在するのです。1988年以降、行政電算網規格PC(政府や地方自治体に納入されるIBM PC互換機)にKS完成型の使用が義務づけられたなかで、常用組み合わせ型に根ざしたワープロソフト「アレアハングル」が支持を集めたのは、ハードウェアによるKS完成型のハングル表示機構を搭載したPC上でも、ハングルの表現に制限がなかったからにほかなりません。
88年から92年にかけては、ハングルコードについての論争が盛んでした。単にKSコードや政府筋の姿勢に対して抗議の声を上げるのでなく、さまざまな解決策が提案され、当時のパソコン雑誌で紹介されたりもしました。しかし、後述する「ソフトウェア・ハングル」によってKS完成型用の表示機構を備えたPC上でも常用組み合わせ型ハングルコードが使えたDOSの時代から、使えるハングルコードが事実上固定されたWindowsなどGUI OSの時代に移りゆくに従い、ハングルコード論争は徐々に下火となって行きました。
KS C 5601は1989年と1992年の2度にわたって改訂が行われました。中でも組み合わせ型文字セットを追加したKS C 5601-1992の制定は、ハングルコード論争を鎮める一因となりました。ただし、KS C 5601-1992における組み合わせ型ハングルコードセットの位置づけは、基本文字セット(完成型ハングル2,350字)に対する補助セットにすぎません。むしろ、それまでもKS完成型と並ぶ業界標準として広く用いられてきた組み合わせ型コードの存在を、事実上追認したところに意義があるといえます。
ただし、多くのOSやアプリケーションのベンダーは、KS C 5601-1992の制定後も、相変わらずKS C
5601-1987に基づいた製品開発を続けています。
余談ですが、やはり1992年夏から、炭酸飲料「ペプシコーラ」がハングルでの表記を変更しました。それまで「![[p'ep'-si-k'ol-ra]](../images/pepsiold.gif) 」だったのを「
」だったのを「![[p'ep-si-k'ol-ra]](../images/pepsinew.gif) 」と改めたのですが、理由は「
」と改めたのですが、理由は「![]() 」がKS完成型ハングルコードの文字セットに含まれていないからというものです。KS完成型コードによる事実上のハングル使用制限の結果といえます。とはいえ、長い期間を経ていったん定着した表記の変更が消費者に認知されるには時間がかかりますから、「」はKS完成型で表記不可能な日常単語として、今なおよく引き合いに出されます。
」がKS完成型ハングルコードの文字セットに含まれていないからというものです。KS完成型コードによる事実上のハングル使用制限の結果といえます。とはいえ、長い期間を経ていったん定着した表記の変更が消費者に認知されるには時間がかかりますから、「」はKS完成型で表記不可能な日常単語として、今なおよく引き合いに出されます。
5) 「統合型」を経てUnicodeへ
Windows 3.x/95、OS/2、Macintosh、UNIXなど主要なパソコン/エンジニアリング・ワークステーションのOSでは、いずれも標準のハングルコードとしてKS完成型が用いられています。
現在のOSのうち、厳密に言えばハングルWindows 95の文字コードはKS完成型ではなく、マイクロソフトがKS完成型をもとに独自に拡張し、11,172文字の現代ハングルをすべて扱えるようにしたKS完成型上位互換の「拡張完成型(後に統合型と改称)」というコードが用いられています。拡張部分の文字並びにKSとの互換性がなく、ソートなどが正常に行われない可能性があるため、1995年のWindows 95のβテスト中にユーザーの猛反発を招いたことから、製品版では標準IMEでコード拡張部分の入力ができないよう、修正が施されました。
一方、ハングル処理の標準化に影響力を持つ「アレアハングル」のハングル&コンピュータでは、1992年に発売したアレアハングル2.0以降、拡張組み合わせ型(HWPコード)という独自のコード体系を採用しています。2バイトの文字コード領域をフルに使って65,536字を収容し、うち32,768文字分の領域をハングル(現代語および古語)に、残りをその他の文字にそれぞれ割り当てています。組み合わせ型と名乗っていますが、実質的には完成型コードの一種です。
このほかにも3バイトコードや、Nバイト(可変バイト)内部処理・固定バイト表示といった提案も行われており、中には実際にプログラムとして実装されたケースもありますが、いずれも標準化に至っているとはいえません。
1995年12月にはUnicode 2.0(ISO/IEC-10646:1993 UCS-2)がKS規格に採り入れられ、KS C 5700-1995となりました。Unicodeが2.0となる過程で韓国の意見がほぼ全面的に採用され、11,172文字の現代ハングルはもちろん、古語や単独字母を含めたハングルのほとんどすべてが網羅されたことから、Unicode 2.0は韓国では幅広く支持を集めています。すでにハングルWindows NT 3.5以降では、Unicode 2.0をベースにKS C 5601-1987(厳密にはMicrosoft統合型ハングル)との変換を行うAPIが実装されており、今後はUnicodeの普及が国・業界を挙げて急速に進むものと思われます。
1) DOS上のハングル環境
ハングルを入力・表示できるハードウェア(ハングルカード)がIBM PC互換機に搭載されたのは、韓国でMicrosoftがMS-DOSのOEMビジネスを開始した1985年のことですが、当時はメーカーごとにいずれも組み合わせ型体系を基本としつつも、コード配列は別々というカオス(混沌)の時代でした。そんなカオスを常用組み合わせ型が平定したのは、初期の本格的ワープロソフトとして幅広く普及した三宝コンピュータの「ポソックル」と、それを他社のMS-DOS上で使うためのハングル表示/入力TSR(Terminate and Stay Resident=いわゆる常駐型)ソフト「THP」(後に「NKP」と改称)の登場によるところが大きいでしょう。
このNKPは、英語版のMS-DOS環境上でもソフトウェアのみによるハングルの表示と、コマンドラインやMS-DOS標準入力ファンクションコールだけを用いるアプリケーションでのハングル入力を可能にするものでした。しかも、三宝コンピュータではNKPのコピーを黙認する立場を取ったことから、三宝製以外のPCを購入したユーザーの間にもNKPが普及して行ったのです。
しかし、NKPはMS-DOSの標準入力を用いていたポソックルと「TGEDIT(三宝コンピュータ製のテキストエディタ、IBMのPersonal Editorの操作体系を踏襲)」以外の、大半のMS-DOSアプリケーションでのハングル入力をサポートしませんでした。つまり、BIOSファンクションコールを用いていたほとんどの英語版のアプリケーション上でハングルを入力することができなかったのです。それもあって、前述の7ビットハングルが歓迎されるに至ったわけです。
広く普及した常用組み合わせ型コードの使用を初めて一般的な英語版ソフトの上でも可能にしたのが、英語環境互換のBIOSファンクションコール・エミュレーションを実現した、チェ・チョルリョン氏作の「ハングル・トケビ(DKBB、1988年)」でした。さらにそれを改良し、拡張ASCII文字セットに含まれる罫線文字の文字化けを最小限にとどめることに成功したのが、ヤン・ワンソン氏による「DKBY(1989年)」です。これらのBIOSエミュレーションによるDOS用ハングル入力/表示ソフトは、「ソフトウェア・ハングル(あるいはソフトウェア・ハングルカード)」または「ハングルBIOS」と総称されています。
ちなみに、この頃韓国のIBM PCの表示環境としては、Hercules Graphic Card(HGC)というモノクロのビデオカード(ほとんどは互換品ですが)が主流でした。Herculesとは、現在もビデオカードの有力メーカーとして著名な米国のHercules Computer Technology社のことです。「ハングルカード」と呼ばれたハングルフォントROM/キャラクタ・ジェネレータ(文字発生機構)搭載のビデオカードも最初はHGCベースだけでしたし、ここまで挙げてきたソフトもいずれもHGC用です。
1990年にはハンメソフトがDOS用の高品質ソフトウェア・ハングル「ハンメハングル」を発表しました。常用組み合わせ型はもちろん、KS完成型もサポートし、「ハナ・ワードプロセッサ」など当時行政電算網の標準ソフトとして普及し始めていた「ハナ」シリーズ(金星ソフトウェア=現LGソフト=製)などを英語DOS上でも使うことを可能にしました。フォントをEMS/XMS領域に展開する機能を採用したり、HGC用とともに初めてVGA用をラインナップしたのも特筆されます。
このハンメハングルと並んで人気を集めたのが、初のBIOSエミュレーションを実現した「DKBB」直系の子孫であるハンド・コンピュータの「ハングル・トケビカード」シリーズで、やはり1990年に発売されています。フォントデータを格納するROMカードを8ビットISAの拡張スロットに挿して使用するようになっていましたが、表示や入力はソフトウェアだけで実現していました。このほかにも、同時期には多数のソフトウェア・ハングルが市販品、あるいはフリーソフトウェアとして流通していました。
一方、表示速度(とくにスクロール)の面でメリットのある、ハードウェアタイプのハングルカードの開発も盛んでした。KS完成型ハングルコードの普及が本格化した1988年以降は、常用組み合わせ型とKS完成型の両方が使えるものが盛んになり、常用組み合わせ型コードも漢字や記号がKS完成型と1対1で対応するKSSMが一般的となりました。代表的なものとして、三宝コンピュータやオムニテック(後に多佑技術に吸収)、佳山電子などの製品が挙げられます。
1993年5月、ハングルWindows 3.1が出荷されました。ハングルWindows 3.0(1991年)では無効にされていたMS-DOSプロンプトのウィンドウ表示(DOS窓)が、ソフトウェア・ハングルHBIOS搭載により可能となり、しかも英語版DOSや日本語のDOS/V環境(英語モード)上でもハングルのDOS窓を扱うことができるようになりました。
2) ハングル処理一体型アプリケーション
日本でいうショップブランドマシンにあたる、「商街組み立てPC」には長い間ハングル版DOSが搭載されず、英語版のDOSが載っているのが一般的でした。これこそソフトウェア・ハングルが登場し、受け入れられていった背景でもありますが、それはまた一方で、ハングル処理を一体化(内蔵)したアプリケーションの登場を促しました。
1989年にはのちにハングル&コンピュータを設立する李燦振氏ら大学生4名の手により、ハングル表示・入出力を内蔵し、英語DOS環境でも利用できるワープロソフトとして「アレアハングル(正確には「ハングル」)」が誕生しました。常用組み合わせ型ハングルコードをベースとしているため、ハングルの表現上の制限がないのも特徴です。
前述のように、Windows 3.1が登場し、韓国のパソコン界がWindows時代を迎える1993年頃には、ハングルコード論争はほぼ収束しましたが、アレアハングルのようなハングル処理内蔵型のアプリケーションが増えたことも論争の鎮静化に一役買っているのかもしれません。現在、ハングル&コンピュータ社ではWindows上でもDOS版の方法論を応用、ハングル処理を一体化し、どの言語のWindows上でもハングルが100%表現可能なWindows版アレアハングルを市販中です。
この方式はテキストエディタや通信ソフトにも採り入れられ、1989年にはハングル内蔵の高速テキストエディタ「VADA」、ハングル内蔵通信ソフト「イヤギ」が登場しました。いずれも大邱の慶北大学校にあるコンピュータ・サークル「ハヌルソ(天の牛)」から生まれたソフトです。現在「イヤギ」はハヌルソのOBによるクンサラム情報通信という会社から商品としてリリースされており、1996年からはWindows版となりましたが、DOS上のフリーソフトウェアとしての最終バージョンであるイヤギ5,3(1992年9月リリース)を今なお利用しているユーザーも、韓国には少なくないようです。
もうひとつ、ハングル処理一体型の通信ソフトといえば忘れてはならないのが、Staticの黄建淳氏らによるシェアウェア「SuperSession」です。このソフトはハングルのみならず日本語の表示にも対応しました。とくに1991年、前年10月の発売以降まだ対応ソフトの少なかったDOS/Vにいち早く対応し、韓国のアプリケーションとして初めて日本で広く認められた快挙は、今なお語り草となっています。NIFTY SERVEにおいて1,000件を超えるダウンロードを記録したのも、画期的な出来事でした。
3) Windowsとハングル
ハングルWindowsは1989年に2.11が、1991年9月に3.0がそれぞれ出荷されましたが、本格的な普及期に入ったのは、やはり1993年5月リリースのハングルWindows 3.1からでしょう。
この公式なハングル版Windows 3.1のリリースに先立ち、92年末にはハンメソフトから「ハンメハングル for
Windows」が発表されました。DOS版のハンメハングルと同じコンセプト、つまり英語版のWindows 3.1に組み込んでハングルを使えるようにしようという製品でした。ハングルWindows 3.1の登場によって役目を終えるというのが大勢の予想であったにもかかわらず、ハングルWindowsではハングルと欧文のTrueTypeフォントの間でベースラインが合わない仕様であったことから、欧文フォントとうまく共存するハンメハングル for WindowsはハングルWindows 3.1発売後も売れ続け、現在も「ハンメハングル for Windows 95」としてその命脈を保っています。
なお、MS-DOS(Ver. 3.3以降)やWindowsでは、複数の文字コードセットを切り替えて使える機能(主として1バイト文字圏用)としてNLS(National Language Support)が提供されていますが、その切り替えの対象となる各文字コードセットをコードページという概念でまとめています。日本語(シフトJIS)のコードページは932、KS完成型ハングルのそれは949です。
また、1993年にリリースされたハングルMS-DOS 6.0以降のMicrosoft製ハングル版OSでは、常用組み合わせ型コードページ(1361)が追加されています。Windowsでは1995年11月発売のハングルWindows 95以降が該当します。
ハングルのキーボード配列には大別して2種類が存在し、いずれもKSとして規格化されています。
ポピュラーなのは「2ボル式」と呼ばれる方式で、字母を子音と母音に分けて配列したものです。ハングル字母が英文配列のアルファベットの範囲内に収まるように工夫されているため、覚えやすいのが特徴です。この2ボル式は、1970年代に考案されたハングル・テレタイプ(文字電信)用のキーボード配列をベースにしています。
一方、入力効率の面で優秀とされるのが、字母を初声・中声・終声に分けた「3ボル式」です。こちらは最初のハングル打字機(タイプライター)であった公炳禹式打字機の流れを汲むものであることから、ハングルの電算化に携わる人々の間で支持を集めました。この3ボル式配列にはいくつかのバリエーションがありますが、ハングルWindows、韓国版Macintosh(Korean Language Kitを含む)の入力プログラム(IMEないしはIM)やワープロソフト「アレアハングル」などでは、通常「3-89」と「3-90」の2種類がサポートされています。「最終字板(字板はキーボードの意)」というのが最新の3ボル式配列ですが、これは古いソフトではサポートされていないことがあります。
なお、日本や中国語圏では幅広く普及しているローマ字入力は、韓国ではまったくと言い切ってよいほど使われていません。アレアハングルなどで「外国人向け」と銘打ってサポートされているのみです。
2ボル式配列が覚えやすいからでしょうね。コンピュータ上でのハングル入力を志す人は、ぜひとも2ボル式か3-90を覚えましょう。某社の汎用入力ソフトでハングルローマ字入力が身についてしまった人も日本には多いようですが、韓国では潰しが効きませんからね。(笑)
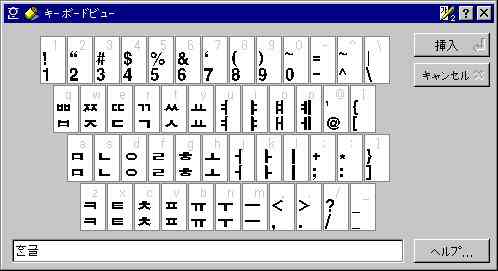
(上)ハングル2ボル式 (下)ハングル3ボル式(3-90)
(画面はいずれもアレアハングル 日本版のもの、106キーボード使用)
※ アレアハングルでは3ボル式に設定した場合、記号キーの配置が欧文101キーボード互換となります。一方、高電社のKorean Writer
V3では、記号配置は106キーボード互換となります。
アレアハングルで3ボル式の記号配置が101キーボード互換となるのは、韓国でOADG配列(ベースはJIS配列)の106/109キーボードが存在しないためです。つまり、字母が記号キーにまで配置されている3ボル式で、記号配置をわざわざ106キーボードに合わせて使い回しの利かないものにするのは無意味であるとの判断に基づいています。
1) パソコン通信
韓国で本格的なパソコン通信が始まったのは、ソウルでオリンピックが開催された1988年のことです。初の有料パソコン通信サービスであるDACOMの「ハングル電子私書函」をはじめ、XENIX(MicrosoftのIBM PC用UNIXクローン)上の多回線ホストによる私設BBS(草の根BBS)としてソウルのEmpal、大邱のタルグボルBBSなどが相次いで誕生しました。DACOMはKS完成型コードを初めて採用、ほかの2つもこれに倣ったとみられます。
翌89年には米国産のIBM PC用BBSホストプログラムである「Wildcat! BBS」が韓国で紹介され、7ビット(清渓川)ハングルコードを用いたBBSホストが普及しはじめました。7ビットが好まれたのは、Wildcat!のような英語版のBBSホストとの相性がよかったためです。
89年9月には後の「HiTEL」の前身となる、韓国経済新聞社によるパソコン通信サービス「クンマウル(大きな村、後に同社のオンライン・データベースサービスKETELに統合)」もオープンしました。この「クンマウル」や後の「KETEL」は長い間無料で運営され、韓国のパソコン通信コミュニティを育てる上で大きな功績を残しました。92年に韓国通信(電話会社)と韓国経済新聞社など数社の出資により、運営会社として「韓国PC通信」が設立されたのを機に「KORTEL」と改称、93年には現在の「HiTEL」として有料化されました。
一方、DACOMもこの年、「ハングル電子私書函」に代わる本格的なパソコン通信サービスとして「PC-VAN」の実験を開始しました。後に「PC-Serve」として有料化され、92年にはオンライン・データベースの「CHOLLIAN(千里眼、1985年開始)」との統合を経て、現在の大手パソコン通信サービス・CHOLLIANとなりました。
90年代に入ると、韓国の私設BBSは一気にバブル期を迎えます。ハングルによるメニュー体系をサポートした韓国産のホストプログラムが、ほとんどはフリーソフトウェアとして多数リリースされ、組み合わせ型ハングルコードをサポートしたBBSが多数オープンしました。筆者が東芝のノートパソコン・DynaBook J-3100SS001にハングル内蔵通信ソフト「ボストーク」をインストールし、国際電話で韓国に繋ぐパソコン通信を始めたのもこの年です。
一方でKETELやPC-Serveのような全国ネットもサービスを拡大し、韓国のパソコン通信の主導権は徐々に草の根から大手商用ネットへと移って行くことになります。
長くHiTEL、CHOLLIANの2大勢力による寡占が続きましたが、94年にナウコムのNownuriが、95年末には三星データシステムによるUNITELがそれぞれ参入、現在の4大パソコン通信サービスが出揃いました。現在のパソコン通信ユーザー数は、4サービス合わせて270万人弱といわれています(「電子新聞」1998年4月20日報道)。
先発2社を含め、いずれも無手順のパソコン通信に加えてPPPによるインターネット接続サービスも提供し、インターネットとの垣根は取り払われつつあります。
なお、1991年には日本のNIFTY SERVEの韓国版として、ポスデータ(浦項綜合製鉄の子会社)の「POS-Serve」が鳴り物入りでスタートし、第3の勢力として期待されましたが、会員数が伸び悩んだまま1996年でサービスを終了しました。
通信ソフトは、草創期のDOS用英語版ソフト(Telix, Procommなど)を経て、この89年は「アレアハングル」や「ハングル2000ワード」といったハングル内蔵型ワープロソフトが誕生した年で、ハングル内蔵のDOSアプリケーション元年といえますが、通信ソフトにもその流れが波及し、「ボストーク("BOSS-NET"という草の根BBSのメンバーが作ったことに由来)」や「タルルン(電話の呼び出し音の擬声語)」、「イヤギ(話)」といったハングル内蔵型通信ソフトも登場しました。
現在ではイヤギのDOS版やWindows版をはじめ、ハングル&コンピュータの「ハンネット(ハングルWindows用)」などが比較的多くのユーザーに使われています。また、ハングルWindows上では、各パソコン通信サービス用の専用通信ソフト(日本で言えば、たとえばNIFTY Managerのような)も提供され、広く利用されています。
2) インターネット
80年代から大学や政府系・民間の研究所などで利用が拡がっていたインターネットは1994年、実験網HANA/SDNを前身とする韓国通信のKORNETと、豊富な回線運用実績を持つDACOMのBORANetが相次いで商用サービスを開始しました。これに大手企業数社の出資を受けたベンチャー企業Inetが加勢し、さらに95年以降、ハンソル、現代、三星、SK、LGといった財閥系企業の新規参入も相次いでいます。
しかし、実際に韓国で個人向けインターネット接続サービスとして最も広く利用されているのは、CHOLLIANなどの4大パソコン通信の提供するダイアルアップ接続サービスです。
また、ほかに主に公的研究機関を結ぶ研究電算網(KREONet)、大学間のネットワークである教育網(KREN)、政府や地方自治体用のKOSINet、PUBNETといった非営利バックボーンも存在します。KREONetは早くから日本のIMNETと接続されており、ひと頃は日韓間で唯一の国際ルートでした。
海外との接続は商用網が主体で、相手は米国がほとんどですが、最近は日本との接続も盛んで、98年からは日韓間で最も太いバックボーンが45Mbps(T3)となりました。
なお、韓国のインターネット・ドメイン(.kr)やIPアドレスの管理を行っているのは、KRNIC(韓国インターネット情報センター)です。
3) インターネットにおけるハングル・メッセージの交換
ところで、インターネットの登場に伴い、新たに浮上してきた問題が電子メールにおけるハングルのやりとりです。KS完成型など漢字文化圏の文字コードは基本的に8ビット体系ですが、インターネットは基本的に7ビット体系でエンコード(符号化)された文字データの通過のみ考慮されており、回線設備などにも7ビットしか通さない、あるいは受け取れないものがあります。
現在、インターネットにハングルを流すのに用いられる一般的なエンコード方法は、2種類です。ひとつはEUC-KRで、これはKS C 5601とKS C 5636(=7ビットASCII文字セット、つまり日本で一般的に言う半角英数ですが、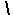 [バックスラッシュ]は
[バックスラッシュ]は![]() になっています)をそのまま(厳密にはいろいろ決まりがありますが)流すやり方です。現在、ニュースグループ(Usenet)とWWWでは、このEUC-KRが用いられているほか、Netscape Navigator
3.0xまでのNetscape Mailや現行のMicrosoft Outlook Expressでも、メールの送信用にEUC-KRエンコードを用いています。
になっています)をそのまま(厳密にはいろいろ決まりがありますが)流すやり方です。現在、ニュースグループ(Usenet)とWWWでは、このEUC-KRが用いられているほか、Netscape Navigator
3.0xまでのNetscape Mailや現行のMicrosoft Outlook Expressでも、メールの送信用にEUC-KRエンコードを用いています。
しかし、欧米などのサーバーを経由してきたハングルメールは文字化け(厳密にはビット欠け)していることも少なくありません。そこで、本来は欧文用のエンコード手段であるQP(Quoted Printable)やBase64を併用することも行われています。
もうひとつは、KS完成型を送信側で7ビットでエンコードし、受信側で元に戻すという方法で、1993年の12月にRFC(Request For Comment、事実上のインターネット標準)としてまとめられたISO-2022-KR(RFC 1557)です。しかし、このISO-2022-KRが定着したのはごく最近のことと言ってよいでしょう。メーラー(MUA=Mail User
Agent、電子メールクライアント、あるいは電子メールソフト)側で長い間サポートされなかったからです。
ISO-2022-KRを普及させたのは、初期には代表的なMTA(Mail Transfer Agent、メールサーバー側に置かれるメール配送プログラム)であるsendmailにKS C 5601←→ISO-2022-KRのエンコード/デコード機能を追加した「ハングルsendmail」の力によるところが大きかったのですが、一般ユーザーがISO-2022-KRを意識するようになったのはMicrosoft Internet MailやNetscape Communicator 4.0xのMessenger(前者は日本語Windows環境でのハングルの扱いに問題がありますが)といった、多国籍メールソフトでのISO-2022-KRサポートによるところが大きかったといえます。
現在のところ、電子メールにおけるハングルのエンコード方法としては最も確実なのがISO-2022-KRですが、ほぼ同時期にまとめられたMIME(Multipurpose Internet Mail Extension、多言語対応を含むメールヘッダの拡張や、メール内容の分割によるファイルの添付方法などを規定)との整合性の問題が指摘されています。たとえば送信側でハングルによるファイル名を持ったファイルを添付した場合、受信側でうまく復元されない場合があります(同様な問題はISO-2022-JP環境でも見られますが)。そこで近年、RFC 1557の改正論議も盛んになりつつあります。
このほか、インターネット標準ではカバーしていない問題ながら、パソコン通信との間の電子メールのやりとりも面倒でした。パソコン通信とインターネット電子メールサーバーの連携が取れず、対策としてパソコン通信側からハングルをUUENCODE(主にバイナリ添付ファイルの送受信に使われるエンコード方式)して送信することが行われていたため、メーラー側でデコード操作を必要としていたのです。現在でも送信側のパソコン通信サービスによってはこの操作が必要となる場合もありますが、最近ではCHOLLIANの「PINE」のように、パソコン通信の画面上であたかもメーラーを扱うかのように操作できるメニューが設けられている例が一般的なようです。
日本におけるコンピュータでのハングル処理への取り組みは、韓国で本格的なコンピュータ産業が立ち上がる1980年代半ばまでは、むしろ韓国より先行していました。Nバイト時代のハングル処理技術の開発には富士通をはじめとする日本企業や、多数の日本人の技術者が関わってきましたし、ハングル電算写植にせよハングルワープロ専用機にせよ日韓/韓日機械翻訳にせよ、いずれも日本で最初に開発されたり、あるいは日本製のハードウェア上に構築されたものです。
パソコン上でハングル処理の可能なソフトウェアは、1980年代からありました。NEC PC-8801などの8ビット機でも動いていましたし、後のPC-9800シリーズ用も含めて共和国(北朝鮮)にはずいぶん輸出されていたものです(ちなみに、PC-9800シリーズの海外における最大の普及地域は共和国だといわれています)。
また、日本電気(NEC)などいくつかの日本のコンピュータ・メーカーは、日本仕様のオフィス向けパソコンとアプリケーションを韓国仕様にローカライズし、輸出(半完成品や部品状態を含む)していました。代表的なものとしてはNEC N5200(三星電管)、日本アイ・ビー・エムのマルチステーション5550(韓国IBM)、富士通FACOM 9450シリーズ(韓国富士通)などが知られています。これらの製品に共通していたのが、今の2ボル式とはやや異なり、キーボードの記号部分に一部の複合子音や母音(韓国標準2ボル式では欧文キーのシフト状態で配置されている)を割り当てた、特殊なキーボード配列です。ハングルロック(日本ではカナロックですね)した状態でシフトキーを可能な限り押さずにすべてのハングルが打てるようにするという、日本のJISキーボードに通じる発想で開発されたものとみられます。
1980年代半ばから90年代はじめにかけては、主としてPC-9800シリーズ上で、さまざまなハングルワープロソフトが開発されました。代表的なものに高電社の「KOA-文書ハングル (後にKOA-TechnoMate ハングルシリーズへと発展)」、しーぴーゆーの「賢筆」などがあり、今もかなりのユーザーが利用しているようです。「賢筆」は、その後の共和国におけるワープロソフトや、その他のハングル処理ソフトのルーツにあたるものです。
これらのワープロソフトは、PC-9800の外字領域を拡張し、そこにハングルフォントを配置することでハングルと日本語の混在表示を実現していました。
1990年にDOS/Vが登場し、日本でもIBM PC互換機の普及が始まりましたが、ソフトウェアフォントというDOS/Vの利点を生かした製品として、高電社から「ハングルドライバー」が発売されました。外字領域にハングルを配置するという方法論はPC-9800用ハングルワープロと基本的に同じですが、最大の特徴はほとんどのDOS/V用日本語アプリでハングルが使えるという、汎用性の高さにありました。
日本語とハングルの混在文書をシフトJISの文字コード体系上で実現する手段として、ハングルをローマ字で表記する方法の開発もひと頃盛んでした。ソウルオリンピックの開催年であった1988年には、PINA(平野洋一郎)氏によってフリーソフトウェア「HT」が開発されました。
HTは、たとえば「 」であれば[han-geul]のように、[ ]で囲んだローマ字表記入りのテキストファイルを読み込ませると、[ ]の部分をハングルに変換して表示するテキストブラウジングソフトです。組み合わせ型コードの原理を採り入れており、11,172文字のハングルをすべて表記できます。
」であれば[han-geul]のように、[ ]で囲んだローマ字表記入りのテキストファイルを読み込ませると、[ ]の部分をハングルに変換して表示するテキストブラウジングソフトです。組み合わせ型コードの原理を採り入れており、11,172文字のハングルをすべて表記できます。
このHTがきっかけとなり、翌1989年、日本のパソコン通信初の韓国のSIG(Special Interest Group, NIFTY
SERVEではフォーラムと呼ばれる)であるPC-VAN(現BIGLOBE PC-VAN)の「SIG-ARIRANG」(1995年閉鎖)が誕生しました。
ARIRANGは日本でのハングル・コンピューティング普及に大きな役割を果たしました。KSや組み合わせ型ハングルコードをHT形式ローマ字に変換する「HCC(CHARM氏作)」のようなHT周辺ソフトも多数開発されましたし、韓国産フリーソフトウェアのデータライブラリが日本で初めて作られたのも、このARIRANGでした。ハヌルソのハングルエディタ「VADA」のPC-9800シリーズへの移植プロジェクト(※)も行われ、PC-9800のMS-DOSにおいて後にも先にも唯一の組み合わせ型ハングルエディタとなりました。
※2 このソフトがARIRANG以外に出回らなかったのは、著作者のハヌルソによって、公開範囲がARIRANGに限定されていたからです。
1994年には、高電社によりWindows(当時はVer. 3.1)上で初めてのハングル入力ソフト「Korean Writer」が開発されました。シフトJISのコード領域にKSコードと同じ並びでハングルを配置した特殊なフォントを用い、フォント切り替えによって日本語のWindowsアプリケーションでもハングル入力を可能にしようという製品です。その後Windows 95の登場に伴って「Korean Writer Plus」となり、現在はKS C 5601コードの入力もできる「Korean
Writer V3」へと発展しています。
このKorean Writerなどのコードは「シフトKS」と俗称されていますが、Korean Writer PlusまでとV3ではやや異なっており、高電社では前者を「SJ」、後者は「KW」と呼んでいます。
Korean Writerに類似した製品として、シージーエスの「WINK97」、オムロンソフトウェアの「kWnn95」もあります。
一方、日本で普及率の高いMacintoshでも、日本のユーザーの間にハングルを扱おうとする動きが早くからみられました。とくに一部の先進ユーザーは、早くから韓国版MacOS「ハングルトーク」を日本仕様のMacに組み込んだり、あるいは互いのモジュールを組み合わせて「合体表示」を行ったりしていましたが、ハングルトークが長い間単品のシステムとして販売されなかったことから、あまり一般的ではありませんでした。1996年も押し迫った頃になってようやく「Korean Language Kit」がアップルコンピュータから出荷され、日本でも手軽に利用できるMac上のハングル環境が整いました。
1997年にはハングル&コンピュータが日本に事務所を開設、同年6月から韓国を代表するワープロソフト「アレアハングル」の日本版を発売し、日本語OS上で初めて11,172文字のハングルを完璧に表現できるワープロソフトとなりました。ただし、韓国製ワープロソフトとして初めて公式に日本で販売されたのは、アレアハングルではありません。Macintosh上ではハンメク・ソフトウェア社による「I-Write(韓国名ハンメクワード)」がWorldScript対応多言語ワープロとして、先に日本進出を果たしています。
このほかハングルに関連する製品として、高電社が韓日および日韓翻訳ソフト「j・ソウル」、インターネットに最適化された韓日翻訳ソフト「i・ソウル/kj」や日韓両用通信ソフト「j・WorldNet」を、大宇電子ジャパンが韓日翻訳ソフト「韓庫君」を、台湾系のダイナラブ・ジャパンがハングルフォントを含むパッケージ「DynaFontお宝パック54書体」やWWWブラウザ用(中国語・ハングル・日本語対応)表示ユーティリティ「AsiaSurf」をそれぞれ発売しています。流通に乗っていないものを含めると、もっとあるかもしれません。